
Assignment: Convert MARC 21 Records to RDF
- Mar 1
- 4 min read
I have a lot of experience converting data from one format to another. Merging companies, software migrations, and changing leadership standards are just a few reasons why I’ve found data conversion so commonplace in my past career. When I read that MARC stood for “machine readable cataloging record,” I was immediately intrigued by the possibility of decoding MARC records with some form of automation.
I decided to take on the challenge and realized quickly just how densely packed the information in MARC records could be. I browsed through the What Is A Marc Record, And Why Is It Important? page again to figure out why I was deciphering code after code to understand the underlying data structure of MARC records.

It was not surprising to learn that it was not a matter of being opaque for opaqueness’ sake– it was a matter of saving computer storage space in the days where 420MB hard drives were considered the norm. Modern programming languages and data schemas often lean towards being human readable as we now have the luxury of storage. I could see an argument for MARC being retired for this reason alone.
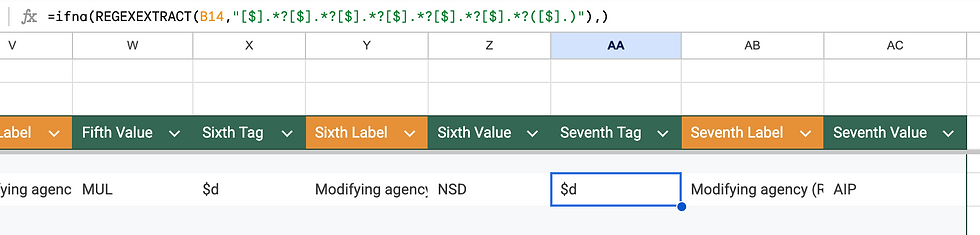

After learning a lot of new (to me) regex and tackling the automation challenge, I also understand why MARC's retirement hasn't happened yet. A lot of work went into making this schema dense and informative, and a lot of work would need to be done to untangle MARC in a way that better aligns it with modern data standards while ensuring compatibility with all the library systems present today. (Although we didn't go in-depth into BIBFRAME in this assignment, I can see how BIBFRAME is still in the process of tackling this challenge.)

Although I began my spreadsheet development project with the goal of extracting and automating the three-digit tag decoding and planned on doing the subfields manually, I wondered if I could also extract and decode the subfields and the indicators. This effort required a bit more effort, but was well worth it. I built three tables: one for the three-digit tags/fields, one for the indicators, and one for the subfields. Each table ensures that the single piece of decoded information is linked to just one label (e.g., 518$a always returns “date/time and place of an event” for each time it shows up in the data).
For me, converting MARC data to RDF was less straightforward than decoding the intricacies of MARC. With MARC, everything had a definitive answer about what the information was supposed to represent, even if that answer was vague or needed additional decoding. There was much more interpretation of the data involved with RDF than I anticipated. I spent a while figuring out which direction each arrow should go when making triples, or if there were nuances to what each schema expected as far as formatting for the subject or object (e.g., date and time formatting). In many cases, I could see either direction working depending on the definition of the predicates, and in some cases using schema.org, Dublin Core, and Friend of a Friend schemas, it was hard for me to see in which "direction" the description was intended to go.

Work Example - Decoder Spreadsheet
Resources
BIBFRAME - Bibliographic Framework Initiative (Library of Congress). (n.d.). [Webpage]. Retrieved March 17, 2026, from https://www.loc.gov/bibframe/
Content designators for bibliographic data. (2018, February 21). OCLC Support. https://help.oclc.org/Metadata_Services/OCLC_MARC_records/Content_designators_for_bibliographic_data
DCMI Metadata Terms. (n.d.). DCMI. Retrieved March 17, 2026, from https://www.dublincore.org/specifications/dublin-core/dcmi-terms/
Dib, F. (n.d.). regex101: Build, test, and debug regex. Regex101. Retrieved March 13, 2026, from https://regex101.com/
FOAF Vocabulary Specification. (n.d.). Retrieved March 17, 2026, from https://xmlns.com/foaf/spec/
google. (n.d.). Re2/doc/syntax.txt at main · google/re2. GitHub. Retrieved March 13, 2026, from https://github.com/google/re2/blob/main/doc/syntax.txt
Hock Chuan, C. (n.d.). Regular Expression (Regex) Tutorial. Retrieved March 13, 2026, from https://www3.ntu.edu.sg/home/ehchua/programming/howto/Regexe.html
MARC 21 Format for Bibliographic Data: Table of Contents (Network Development and MARC Standards Office, Library of Congress). (n.d.). Retrieved March 17, 2026, from https://www.loc.gov/marc/bibliographic/
RDF 1.1 Primer. (n.d.). Retrieved March 17, 2026, from https://www.w3.org/TR/rdf11-primer/
REGEXEXTRACT - Google Docs Editors Help. (n.d.). Retrieved March 13, 2026, from https://support.google.com/docs/answer/3098244?hl=en
RegExr: Learn, Build, & Test RegEx. (n.d.). RegExr. Retrieved March 13, 2026, from https://regexr.com/
Schemas—Schema.org. (n.d.). Retrieved March 17, 2026, from https://schema.org/docs/schemas.html
Understanding MARC Bibliographic: Parts 1 to 6. (n.d.). Retrieved March 17, 2026, from https://www.loc.gov/marc/umb/um01to06.html
Comments